

Ogni consulente SAP BW agli inizi ha dovuto confrontarsi e scontrarsi con uno degli ostacoli apparentemente più difficili ed ostici di questo lavoro: il codice ABAP
Questo è il primo di una serie di articoli che affrontano questo problema partendo dalle basi. Pian piano scopriremo che, superato l’impatto iniziale, il codice può diventare un alleato e non un ostacolo.
Ma facciamo qualche salto indietro e partiamo dai fondamentali: cosa sono e come si usano le tabelle interne
Tabelle interne
SAP BW è un DB che si basa su tabelle
SAP BW è uno dei più famosi ed importanti datawarehouse sul mercato.
Il suo compito principale è quello di aggregare i dati per fornire dei report che possano essere letti ed interpretati dai decision maker.
Come ogni datawarehouse lavora con delle strutture atte ad accogliere e manipolare i dati (se vuoi approfondire il concetto di DWH leggi questo articolo Cos’è un Data warehouse e perchè serve alla tua azienda).
Molto spesso si presenta la necessità di leggere delle informazioni storicizzate in altri datatamart (altre strutture contenenti dati).
La potenza del DWH è proprio quella di riuscire ad uniformare informazioni provenienti da diverse fonti dati ed arricchire il corredo informativo presente nella nostra struttura. Se ad esempio stessimo lavorando su una struttura contenente le fatture inviate ai clienti ed avessimo bisogno di avere informazioni di carattere anagrafico dei clienti, potremmo aver necessità di scrivere codice ABAP per rileggere tali informazioni.
Avremmo quindi una situazione di questo tipo:
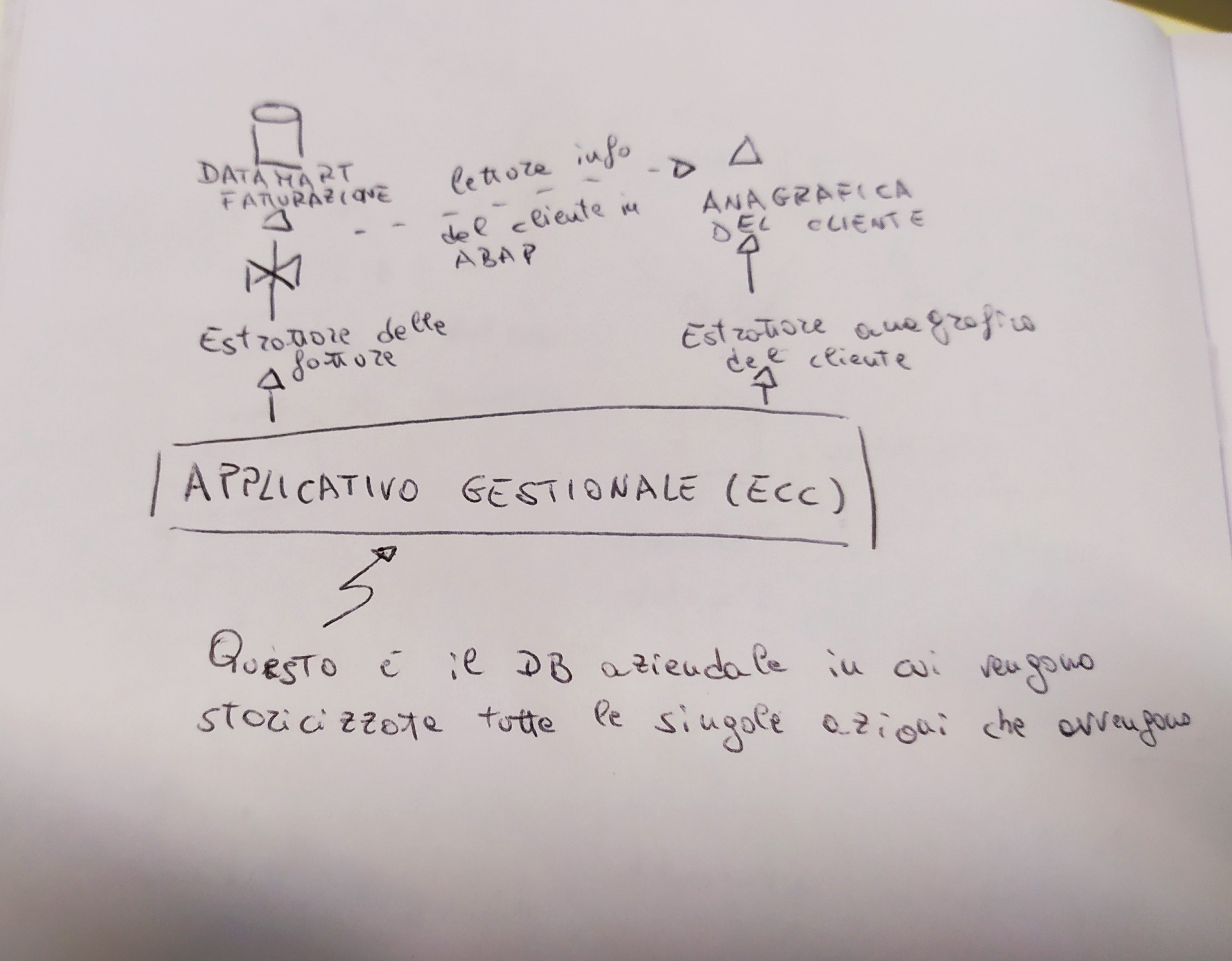
In cui dal DB estraiamo in un flusso dati le fatture ed in un altro flusso dati l’anagrafica del cliente.
Nel flusso della fatturazione vogliamo arricchire le informazioni con i dati anagrafici del cliente estraendo ad esempio il nome e cognome del cliente e da quanto tempo è nostro cliente.
Faccio due premesse:
- Spero che si riesca a leggere la mia scrittura (per fortuna di solito utilizzo il computer per scrivere 😊 )
- L’esempio che ho fatto serve a rendere un po’ più concreta la situazione in cui ci troviamo e so che nel caso specifico non è indispensabile scrivere codice per estrarre le informazioni di carattere anagrafico e ci sono anche altre soluzioni tecnicamente perseguibili, tuttavia volevo portare un esempio facilmente comprensibile.
Tabelle interne e tabelle fisiche
A questo punto siamo pronti a scrivere il nostro codice ABAP per leggere il nome e il cognome del cliente.
Le informazioni anagrafiche sono contenute in una tabella (tipicamente la tabella P dell’anagrafica) che è una tabelle fisica ossia una tabella fisicamente presente sul DB di BW.
All’interno del nostro programma ABAP non possiamo utilizzare le tabelle fisiche ma possiamo solamente leggerle. Per questo motivo abbiamo bisogno di estrarre tali informazioni ed inserirle in un’oggetto utilizzabile nel codice.
Tale oggetto prende il nome di tabella interna che è una tabella “virtuale”, una tabella cioè non esistente nel Data Base ma che “nasce e muore” all’interno del nostro programma. Per tale ragione abbiamo necessità di creare questa tabella, definire quali colonne la compongono e che tipologia di dati saranno presenti in ogni colonna, riempire tale tabella con i dati che ci servono e infine leggere i dati per utilizzarli nella nostra struttura finale.
Tipologie di tabelle interne
Esistono differenti tipologie di tabelle interne con caratteristiche peculiari per ognuna di queste che ora approfondiamo insieme.
La scelta della tipologia di tabella interna da utilizzare è molto importante e influenzerà le perfomance e le tempistiche del programma.
Standard Table
La prima tipologia di tabella è la standard table che è la tabella interna più semplice.
È una tabella interna per cui non è necessario definire la chiave e pertanto è possibile avere più righe duplicate.
In questa tabella dovremo solamente definire quali sono le colonne e che tipologia di dati devono contenere tali colonne (char, numerici, date ecc).
PRO:
- Tabella molto semplice da definire
- Non è necessario ragionare su quale sia la chiave univoca
- molto veloce da riempire
- è possibile sortarla (ossia ordinarla) in qualsiasi modo
CONTRO:
- Lettura dei dati da questa tabella molto lenta perché non c’è una chiave e pertanto l’unico modo in cui si può leggere è in maniera sequenzale, ossia riga per riga (ci sono delle strategie per migliorare l’algoritmo di lettura come ad esempio la binary search che tuttavia non approfondirò in questo articolo)
Il contro che ho indicato è da tenere bene a mente in quanto inficia in maniera molto importante le performance e di conseguenza le tempistiche di caricamento.
Fare una read table su una tabella di tipo standard è una delle cose meno performanti in assoluto in quanto la lettura non avviene per chiavi della tabella.
Solitamente quindi tale tabella viene usata quando:
- Abbiamo necessità di ordinarla
- Dobbiamo looparla e non leggerla
Sorted Table
Passiamo alla seconda tipologia di tabella interna.
La sorted table è una tabella interna di cui dobbiamo definire la chiave (ossia il campo o la combinazione di campi per che rende la riga univoca).
Come dice il nome stesso, tale tipologia di tabella ha un ordinamento definito a monte e di conseguenza man mano che i dati vengono immessi nella tabella verranno ordinati in un modo ben preciso.
I campi che determinano l’ordinamento sono quelli presenti nella chiave stessa della tabella (ecco perché se abbiamo necessità di sortare la tabella per campi differenti abbiamo necessità di utilizzare una standard).
Questa è una tabella nettamente più performante in fase di lettura in quanto le righe sono ordinate secondo una chiave ben precisa ed inoltre la read avverrà per chiave (totale o parziale).
PRO:
- Tabella molto più perfomante in fase di lettura
- Tabella ordinata secondo una chiave precisa e pertanto se avessi necessità di looparla so a priori che
- la riga successiva potrebbe avere la stessa chiave ( o parte di essa) di quella che sto analizzando
- se non fosse così non troverò più una riga con quella chiave o parte di essa
- Mi costringe a ragionare sulla chiave e pertanto riesco a prevedere quale sarà la granularità dei dati
CONTRO:
- Non posso sortarla
- Leggermente più lenta in fase di acquisizione dati
Esistono due sotto- tipologie di tabella sorted che ora andremo ad analizzare.
Sorted table with unique key
Abbiamo detto che nella sorted table abbiamo necessità di definire una chiave che verrà utilizzata dall’algoritmo per ordinare i dati.
La cosa più immediata da pensare è che questa chiave debba essere univoca, ossia che non possono esistere due righe con la stessa chiave.
Quando dico che non possono esistere due righe con la medesima chiave intendo dire che dobbiamo esserne sicuri perché qualora esistessero, il programma andrebbe in errore (generando un dump).
Di conseguenza dobbiamo conoscere e comprendere la granularità della tabella fisica che andiamo a leggere prima di definire la chiave della nostra tabella interna. Una situazione in cui siamo sicuri che non possano esistere righe duplicate si verifica quando definiamo la chiave della tabella interna utilizzando la stessa chiave della tabella fisica che leggiamo (ogni tabella fisica ha una chiave che è per definizione univoca).
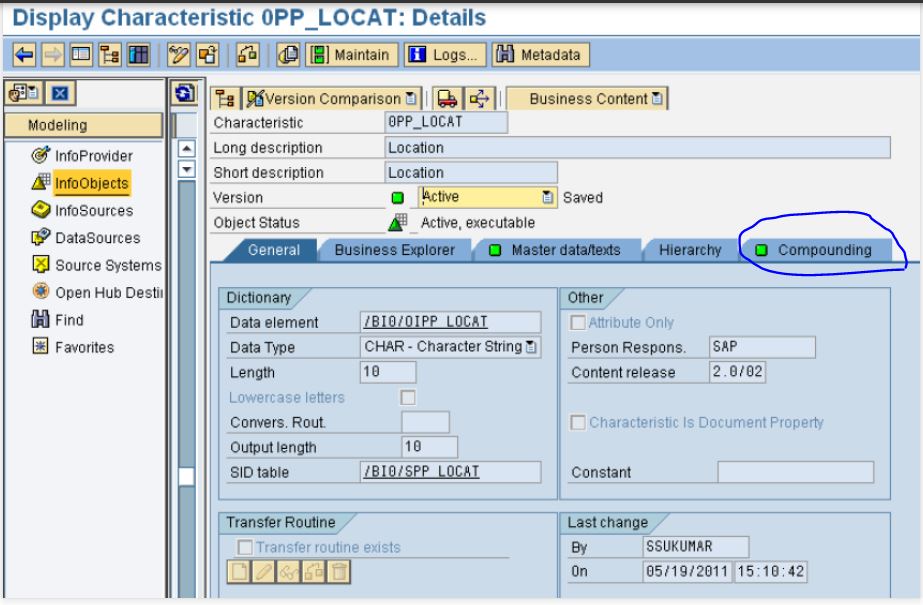
Nell’esempio di apertura dell’articolo, ossia nel caso in cui leggiamo un’anagrafica, siamo sempre sicuri di riuscire ad individuare una chiave univoca in quanto l’anagrafica ha per definizione come chiave l’oggetto di riferimento (nel nostro caso il cliente) ed eventuali compound (ossia altri infobject in relazione inscindibile con il cliente che vanno a formare la chiave dell’anagrafica). I compound sono facilmente individuabili guardando l’anagrafica in quanto esiste un tab apposito contenente appunto i compound (o relazioni inscindibili):
Sorted table with NON-unique key
Infine abbiamo la possibilità di utilizzare una tabella di tipo sorted anche nel caso in cui pensiamo che la chiave che andiamo a definire non sia univoca.
La tabella sorted with non- unique key infatti ha la possibilità di accogliere chiavi duplicate senza che il programma vada in errore.
L’algoritmo ordinerà in base alle chiavi che abbiamo definito e quindi potrebbero esistere più righe consecutive con la stessa chiave.
Questa casistica si verifica quando dobbiamo leggere una tabella fisica e il nostro obiettivo è quello di ottenere una granularità differente (perché ad esempio non ci interessa conoscere una delle chiavi della tabella fisica oppure perché decidiamo di voler poi aggregare i dati sommandoli e riducendone quindi la granularità).
Hashed Table
L’ultima tipologia di tabelle interne esistenti è l’hashed table.
Prima di addentrarci nel suo utilizzo, è importante specificare che questa tabella viene usata ed è molto performante nel caso in cui ci aspettiamo di andare ad inserirvi una grandissima mole dati.
L’hashed è una tabella che richiede necessariamente una chiave univoca e qualora esistano due righe con la medesima chiave il programma dumperebbe. Siamo in una situazione molto simile alla sorted with unique key e pertanto è necessario conoscere a priori la granularità dei dati che andranno a confluire nella tabella.
L’algoritmo definisce autonomamente degli indici che permettono di ottimizzare la lettura della tabella e quindi diventa estremamente performante leggere una tabella di questo tipo.
Tuttavia, la generazione degli indici richiede un tempo (di pochi millisecondi) che si va a pagare in fase di select ossia nella fase in cui la tabella viene riempita.
Per tale ragione, nel caso in cui tale tabella dovrà ospitare diverse decine di migliaia di righe (o addirittura milioni), il tempo necessario alla generazione degli indici viene abbondantemente ripagato in fase di lettura. Se invece dobbiamo inserirvi poche decine di righe andremmo a perdere del tempo in fase di select che non riusciremmo a recuperare in fase di lettura. Sarebbe come decidere di prendere una ferrari per girare nel centro città pieno di semafori.
PRO:
- Estrema velocità in fase di lettura
- Chiave univoca e pertanto siamo costretti a ragionare sulla chiave e pertanto sulla granularità
- Tabella ottima in caso di moli dati molto importanti
CONTRO:
- Se la chiave univoca non è rispettata il programma dumpa
- Sconsigliata utilizzarla per moli dati piccole
Conclusioni
E con questo terminiamo la carrellata sulle principali tipologie di tabelle interne.
Ovviamente abbiamo visto solamente una prima parte del loro utilizzo in quanto dovremo ancora soffermarci su come definirle, come farvici confluire i dati e poi come poterli utilizzare.
Sono convinto tuttavia che questa prima infarinatura teorica sia fondamentale nella fase di scelta della tipologia e che aver bene a mente le differenze tra le diverse tabelle semplificherà il lavoro successivo in quanto saremo in grado di scegliere la tabella in base all’utilizzo che vorremo farne nel corso del programma stesso

Sono un consulente di Business Intelligence,lavoro con uno dei software di Business Intelligence più importanti e completi sul mercato che è SAP BW (da poco diventato BW4HANA), e ho avuto modo di lavorare con grandissime realtà nazionali ed internazionali.
In tutte queste realtà ho avuto modo di entrare nella vita aziendale conoscendone i processi, i problemi, e le necessità e di relazionarmi con key user, decision maker, manager e personale operativo per riuscire a costruire report e dashboard che facilitassero il loro lavoro e permettessero in pochissimi click di ottenere tutte le principali informazioni sull’andamento della società.
Ho iniziato a fare divulgazione sul tema Business Intelligence per spiegare anche ai non addetti ai lavori quanto sia importante ragionare sempre in funzione di dati e come sfruttare la tecnologia per prendere decisioni migliori.
Le informazioni hanno un valore inestimabile e sono la cartina al tornasole di qualsiasi business mentre i dati da soli sono solo numeri!

