In questo articolo vedremo come il Cloud e BW4hana abbiano rivoluzionato le best practies di sviluppo e come la virtualizzazione dei dati stia assumendo un ruolo sempre più importante nei progetti di BI
Cos’è SAP BW4/hana
Da qualche anno SAP ha rivoluzionato, di nuovo, il mondo della Business Intelligence grazie ad una nuova tecnologia che ha cambiato il modo di creare modelli dati e dato maggiore flessibilità e velocità di analisi all’utente finale permettendo anche di effettuare analisi in real time.
Tutto questo ottenendo anche un costo totale di proprietà (TCO) minore.
Questa rivoluzione porta il nome di SAP BW4/Hana.

In questo articolo vedremo le caratteristiche principali e rivoluzionarie di questo strumento e scopriremo l’importanza che la virtualizzazione dei dati ha assunto nell’era del cloud.
Road map e breve storia di BW4Hana
L’attuale realise di BW4/hana è il risultato di oltre 5 anni di lavoro da parte di SAP che, attraverso varie innovazioni, è passata dal “classico BW” ad un software di Business Intelligence completamente in cloud e dalle performance eccellenti.
Per raggiungere tale scopo si è passato attraverso diversi step che nell’ordine sono stati:
- Aumento e miglioramento delle performance
- Ottimizzazione dei processi di virtualizzazione
- Integrazione con la piattaforma HANA e integrazione dei Big Data
- Per giungere infine al BW4/HANA
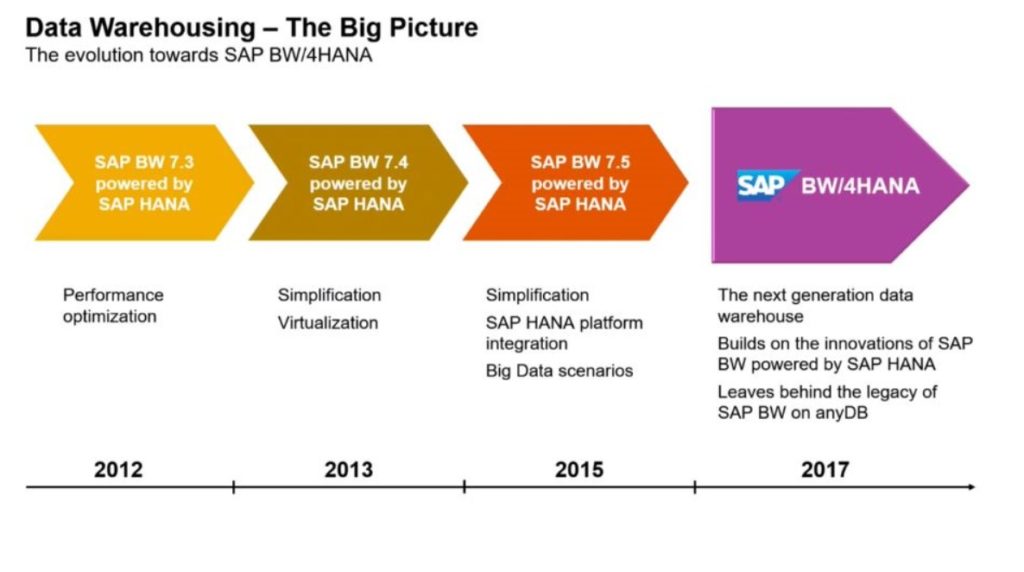
Figura 1- Road map BW4/HANA - Fonte OpenSAP
Ovviamente altre innovazioni in casa SAP (in primis lo sviluppo di HANA e di S4/HANA) hanno influenzato tale road map.
Nuove Best practices
L’introduzione di BW4/hana ha cambiato e in alcuni casi rivoluzionato il modo in cui si creano i modelli dati.
Lo spazio occupato sul DB, prima di BW4/HANA era un tema davvero poco discusso.
D’altronde l’azienda aveva acquistato uno o più server dedicati a BW e pertanto lo spazio a disposizione era stato acquistato, immobilizzato e messo a disposizione (ovviamente questa affermazione non era sempre vera perché dipendeva dalla mole dati creata e dalla configurazione dei server).
L’avvento del Cloud ha ovviamente stravolto questo modo di pensare in quanto di fatto non si è più costretti ad acquistare un proprio server dedicato ma si “può prendere in affitto” lo spazio da un fornitore (tipicamente Amazon AWS).
Sembra un piccolo cambiamento, ma in realtà ha apportato enormi differenze. È paragonabile alla differenza che esiste tra acquistare casa e prenderla in fitto (con la possibilità di lasciarla in qualsiasi momento e non avendo immobilizzato ingenti investimenti iniziali) e questo ha avuto un enorme impatto sul TCO (total cost of ownership) che si è drasticamente abbattuto.
Ma ha posto notevolmente l’accento anche sulla tematica dello spazio occupato a causa della presenza di dati duplicati o comunque ridondanti.
Ed ecco che sono nate nuove best practies tra cui le più importanti sono legate alla:
- Virtualizzazione dei dati
- Niente dati duplicati
- Presenza di dati caldi, tiepidi e freddi
Virtualizzazione dei dati
Questo è uno dei temi maggiormente discussi dall’avvento di BW4/hana (tanto che ha dato il titolo all’articolo).
Prima di addentrarci nel tema riporto un’immagine presa da uno dei progetti su cui sto lavorando in qualità di consulente senior su SAP BW4/hana:
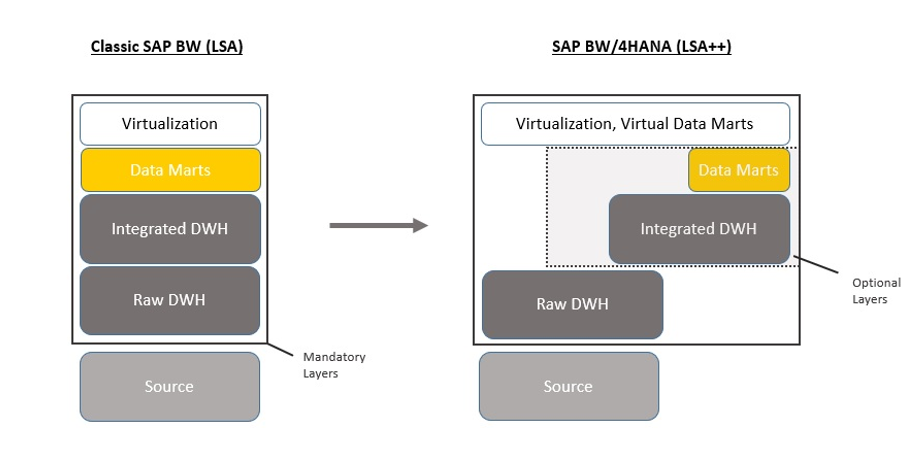
Figura 2- Virtualizzazione delle architetture dati
Questo grafico era riportato in una slide che riassumeva i vari obiettivi del progetto.
Proviamo a guardare i due schemi partendo da quello a sinistra.
Classica architettura SAP BW
La classica architettura di SAP BW nelle release precendenti a BW/4HANA era rappresentata:
- Persistent Staging Area (PSA) che era una tabella di sistema (utile solo a fini tecnici) che storicizzava i dati estratti dal sistema sorgente (ECC, file ecc). Non effettuava alcuna operazione né era possibile effetuare regole di transcodifica o aggregazione dei dati a questo livello. Questo livello è stato completamente eliminato in BW/4HANA
- Primo livello o Staging Area era il primo Data Mart (ossia la prima struttura per accogliere e manipolare i dati) del modello dati. Anche in questo livello normalmente non venivano effettuate logiche, se non piccole transcodifiche e pulizie dei dati, ma si tendeva ad utilizzare tale struttura come una “area di atterraggio dei dati” .
- Altri livelli fisici (almeno 1 ma tendenzialmente più livelli): Questa era la parte di DWH vera e propria. Era costituita da tutti i livelli di data marts utilizzati per effettuare le manipolazioni ed aggregazioni necessarie affinchè il dato fosse pronto per la query finale.
- Un livello opzionale di virtualizzazione (Multicube): nel caso in cui fosse necessario unire i dati di più strutture finale mediante una union era possibile effettuare tale operazione mediante un livello virtuale. Tale livello non creava una nuova tabella fisica a sistema ma era in grado di effettuare solamente una union e non era possibile inserire ulteriori logiche.
- Query (“livello” virtuale): la query era il punto di arrivo di un flusso dati. Il risultato da poter utilizzare per ottenere finalmente le informazioni desiderate. È ovviamente un “livello” virtuale in quanto non vengono storicizzate tali informazioni ma si interrogano in maniera virtuale i dati presenti nel livello sottostante.
Perchè era necessario utilizzare molti data mart
Come si può facilmente intuire dalla breve trattazione, vi erano molti livelli di dati ridondanti ed inoltre tutto il core del flusso era pensato per essere ospitato da data marts fisici (ossia scritto fisicamente in qualche tabella del sistema, occupando spazio di archiviazione fisico sul server).
È facile intuire il motivo di tale scelta. La fortuna di BW (che in origine si chiamava BIW) fu quella di sfruttare job di caricamento notturno per memorizzare i dati ed offrire una rapida e performante analisi.
Ovviamente il focus era rivolto ai dati passati e non di certo ad analisi in tempo reale o addirittura analisi previsionali sul futuro. Pertanto tale architettura assicurava stabilità e robustezza ai modelli dati e di essere interpretati molto velocemente.
Architettura implementativa su BW4/hana
Con l’avvento del cloud e le performance nettamente migliorante dall’avvento di Hana (con un miglioramento di 10x se non maggiore), non era più pensabile strutturare un flusso con tutti questi livelli fisici. Tutto questo spazio fisico destinato ad archiviare innumerevoli volte gli stessi dati, sono diventati un costo per l’azienda che deve allocare altro budget per prendere ulteriore spazio.
L’esigenza di analisi in tempo reale inoltre ha notevolmente modificato le abitudini di analisi. Per report particolarmente complessi e onerosi, o per analisi a consuntivo di fine mese può aver senso analizzare i dati che sono stati storicizzati durante la notte precedente.
Tuttavia gli scenari di business, e di conseguenze le esigenze di analisi dei dati, sono diventate molto più veloci e c’è necessità di fare analisi in tempo reale. Per questo tipo di analisi non è pensabile aspettare al giorno successivo per analizzare i dati.
Tutti questi fattori ci portano verso la parte destra dell’immagine
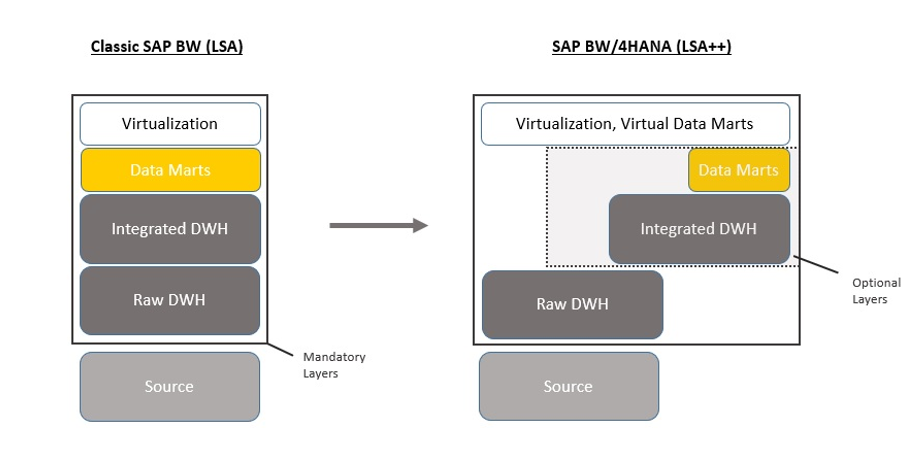
È lampante quanta importanza abbia assunto la virtualizzazione del dato e di come le strutture fisiche siano pensate solamente come staging area ossia strutture attrezzate per accogliere i dati grezzi (raw data).
Ovviamente questa nuova architettura va sempre più verso il mondo dei big data e la loro integrazione con report e analisi basate su dati strutturati.
Articolo di approfondimento
Ho pubblicato qualche giorno fa un caso studio molto approfondito sul tema della virtualizzazione del dato dal titolo SAP BW4HANA, COME LA VIRTUALIZZAZIONE DEL DATO PUO’ EVITARE MODELLI COMPLESSI E INUTILI RIPRESE DATI | CASO STUDIO in cui riporto un caso studio di uno sviluppo su BW4HANA sfruttandone le funzionalità della virtualizzazione del dato e delle calculation view e confrontarlo alle possibili soluzioni alternative che si sarebbero dovute implementare su un BW7.

È un articolo molto dettagliato che può essere visto come:
- una guida step by step su come impostare un modello virtuale,
- Una guida su come creare delle calculation view
- un esempio pratico di come gestire tutte le fasi di un progetto
- come effettuare le analisi del caso
- un approfondimento sulle differenze implementative tra BW4HANA e il BW7
No ai duplicazioni dei dati
Un aspetto importante derivante da quanto già espresso nei paragrafi precedenti e legati alla sempre maggiore attenzione allo spazio utilizzato, è la decisione di eliminare il fenomeno dei dati ridondanti e duplicati.
Come ampiamente discusso nel paragrafo precedente, l’architettura di BW 7.4 presupponeva diversi data layer contenente gli stessi dati aggregati in maniera differente.
Accadeva spesso infatti che un’informazione fosse presente in BW all’interno di molti flussi dati differenti e questo sia per gestire aggregazioni differenti che per poter integrare tale informazione all’interno di report e di analisi differenti.
BW 7 – Un data mart per ogni “angolo” informativo
Prendiamo come esempio i dati del fatturato. Nel classico flusso dati di BW 7 (ossia versioni precedenti rispetto a SAP BW4/HANA) c’era un primo livello in cui venivano storicizzati i dati del fatturato senza fare alcuna elaborazione.
Questo era un livello di data staging a cui seguiva generalmente un secondo livello in cui venivano fatte le prime logiche (trascodifiche, aggregazioni e aggiunta di informazioni di carattere anagrafico).
Questo livello rappresentava la base dati per tutte le analisi relative al fatturato.
Tuttavia questo non significa che tutte le query fossero eseguite direttamente su questa struttura, anzi molto spesso da questa struttura venivano alimentati diversi flussi specifici per alimentare precise necessità informative.
Poteva esistere ad esempio una struttura contenente solamente il fatturato aggregato ai fini della pianificazione finanziaria, un flusso che congiungesse il fatturato al flusso contenente le imposte e l’IVA ecc.
Riporto di seguito un esempio relativo ad un’azienda del settore delle utility (energia elettrica, gas, acqua ecc) relativa proprio ai flussi che partivano dal fatturato:
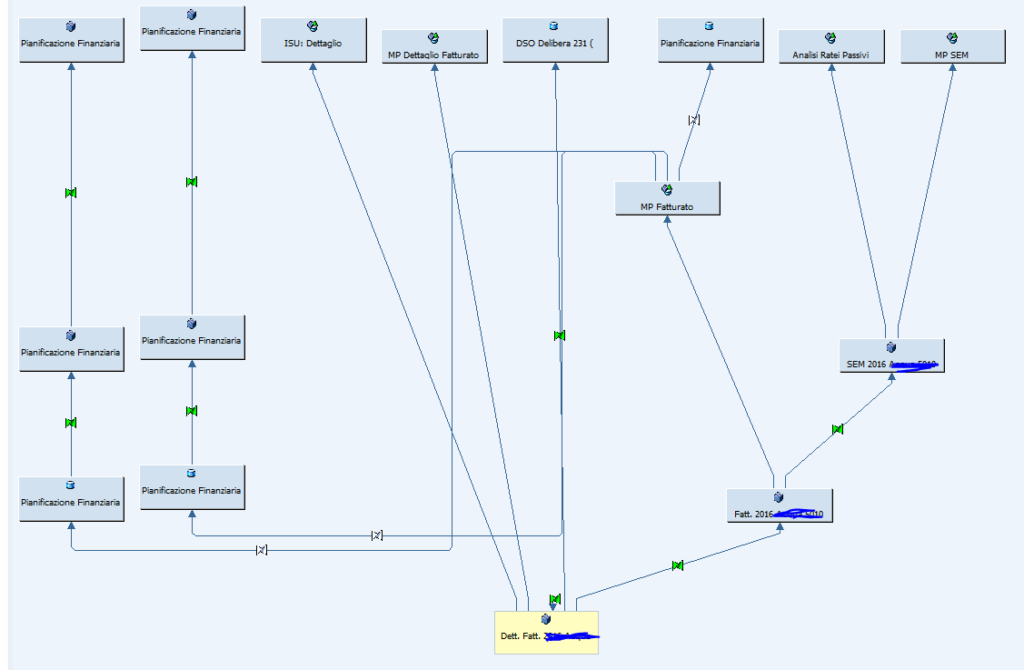
Figura3 - Flusso su BW7.4 - Progetto su cui ho lavorato
L’esempio riportato mostra decine di strutture create a partire dalla medesima base informativa e ognuna di queste strutture (ad eccezione di pochissimi multiprovider) scrivevano effettivamente dati in tabelle fisiche del sistema.
Questo è il classico esempio di flussi riportanti dati ridondanti .
BW4/hana: eliminazione dei dati ridondanti grazie alla virtualizzazione
Nella nuova ottica di BW4/HANA questa tipologia di implementazione va contro le linee guida redarguite dalla SAP stessa.
Lo stesso flusso dati si andrebbe a costruire utilizzando uno o due livelli fisici da utilizzare per le strutture virtuali (composite provider e calculation view ad esempio).
Questa nuova modalità di implementazione riduce notevolmente lo spazio fisico occupato dal DB (minimizzando i costi del cloud).
Dati caldi, tiepidi e freddi

L’ultimo aspetto correlato con quelli precedenti è l’introduzione e il rafforzamento del concetto di archiviazione dei dati.
I dati, sulla base di quanto tempo fa si sono originati, possono essere suddivisi in tre categorie:
- Caldi: ossia dati relativi a periodi temporali recenti (1-2 anni al massimo)
- Tiepidi: dati relativi a tempi non proprio recenti ma che non possono essere del tutto archiviati
- Freddi: dati relativi a periodi di tempo molto lontani
Dati caldi
I dati caldi sono ovviamente quelli di maggiore interesse per le aziende in quanto sono relativi a periodi di tempo utili per le analisi e per poter prendere decisioni basate sui dati (data driven ).
Pertanto tali dati sono facilmente accessibili e sempre disponibili sul DB.
Dati tiepidi
Quando i dati superano i due anni di longevità diventano tiepidi (in quanto potrebbero rientrare in analisi specifiche tuttavia hanno perso il carattere di utilità che li contraddistingueva precedentemente). In questo momento vengono spostati in una zona del DB ancora accessibile ma che richiede elaborazioni più lunghe. I dati vengono parzialmente compressi in modo da occupare meno spazio ma essere comunque ancora leggibili.
Dati freddi
Quando i dati diventano molto vecchi ossia freddi, tendenzialmente dopo 5 anni, vengono compressi completamente e non sono interrogabili mediante i classici report BW. C’è necessità di consultare l’archivio e decomprimere tali dati.
Anche queste azioni di archiviazione ovviamente hanno l’obiettivo di ridurre sempre maggiormente lo spazio occupato dai dati sul DB.

Sono un consulente di Business Intelligence,lavoro con uno dei software di Business Intelligence più importanti e completi sul mercato che è SAP BW (da poco diventato BW4HANA), e ho avuto modo di lavorare con grandissime realtà nazionali ed internazionali.
In tutte queste realtà ho avuto modo di entrare nella vita aziendale conoscendone i processi, i problemi, e le necessità e di relazionarmi con key user, decision maker, manager e personale operativo per riuscire a costruire report e dashboard che facilitassero il loro lavoro e permettessero in pochissimi click di ottenere tutte le principali informazioni sull’andamento della società.
Ho iniziato a fare divulgazione sul tema Business Intelligence per spiegare anche ai non addetti ai lavori quanto sia importante ragionare sempre in funzione di dati e come sfruttare la tecnologia per prendere decisioni migliori.
Le informazioni hanno un valore inestimabile e sono la cartina al tornasole di qualsiasi business mentre i dati da soli sono solo numeri!